flowchart LR
Toolkit["Cuda Toolkit (runtime, libararies)"] --> Driver["Cuda Driver (libcuda.so)"]
Driver["Cuda Driver (libcuda.so)"] --> Kernel["Kernel mode nvidia.ko"]
Kernel --> GPU
Operating system and docker notes for GPU
Notes
GPU
LLM
kubernetes
moe
benchmarking
deep-learning
1 Introduction
This part is mainly for my own understanding of GPU topics and topics which I come across. This is in no way shape or form complete or comprehensive list of topics for GPU optimization techniques and theories
1.1 OS, Docker and kubernetes for GPU
Even with high end gpus, performance can be bottlenecked by OS, CPU, memory. The fastest gpu is only as good as the data feeding it.
1.1.1 CPU and operating system settings
For operating system, an important parameter is swapiness, this determines if OS will pull the pages from RAM to slower hard drive based swap space. Keeping vm.swapiness=0 prevents swapping to take place and keeps the data in RAM (until its full of course).
Cuda driver interfaces with the actual device and the cuda driver interacts with the GPU to enable its features
GPU programming model is compatible across different generations of hardware. This allows JIT compilation for GPUs so that their code can run on the newer hardware.
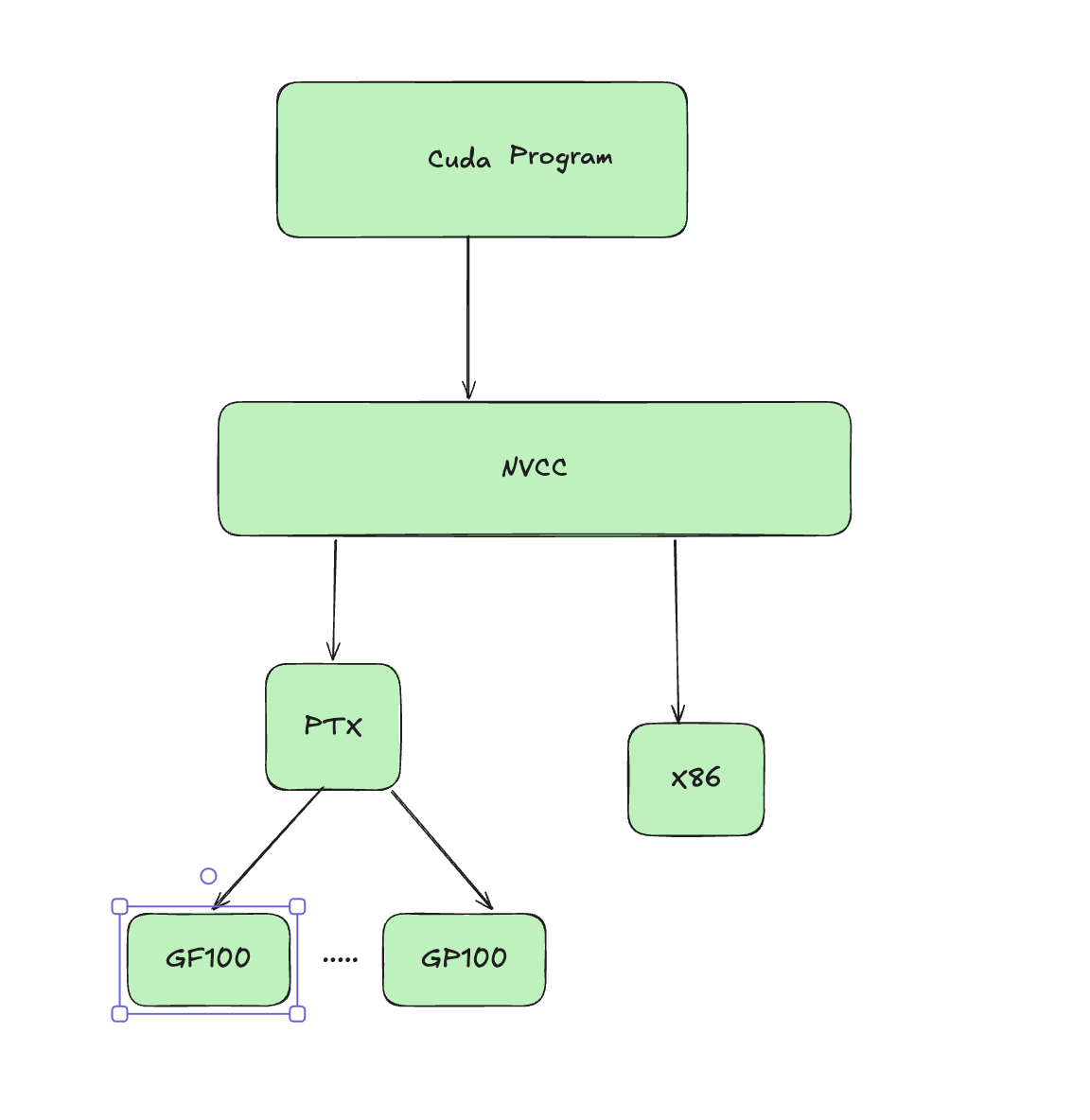 When compiling cuda code, you produce CUBIN and PTX Now PTX is just an intermediate representation which can be used by CUDA to compile (JIT) older programs to the newer GPU. CUBIN is the architecture level SASS (Streaming assembler) which is needed for a specific architecture you are compiling for today.
When compiling cuda code, you produce CUBIN and PTX Now PTX is just an intermediate representation which can be used by CUDA to compile (JIT) older programs to the newer GPU. CUBIN is the architecture level SASS (Streaming assembler) which is needed for a specific architecture you are compiling for today.
CUBIN is fast to load but locked for specific GPU, whereas PTX code is forward compatible. A FAT Binary or Fatbin just bundles both of them together and you need to ship both for it to be compatible.
1.1.2 Frameworks
Many python based frameworks like pytorch and keras are build on top of CUDA. The PyTorch compiler stack consists of TorchDynamo, AOT Autograd, and a backend like TorchInductor or Accelerated Linear Algebra (XLA), which automatically capture and optimize your models. TorchInductor is the most common backend, and it uses OpenAI’s Triton under the hood.
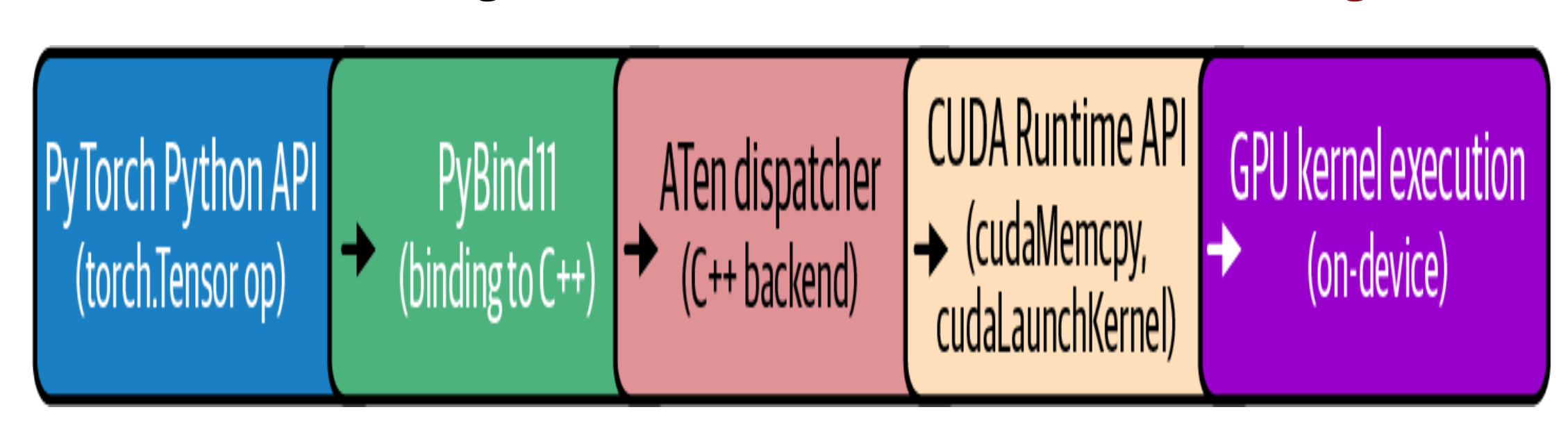 {fig-architecture fig-alt=“Pytorch compilation for cuda”}
{fig-architecture fig-alt=“Pytorch compilation for cuda”}
While performing matrix multiplications, PyTorch delegates these tasks to libraries such as cuBLAS. cuBLAS is part of the CUDA Toolkit and optimized for GPU execution. Behind the scenes, PyTorch ensures that operations like forward and backward passes are executed using low-level, optimized CUDA functions and libraries.
1.2 CPU affinity and NUMA (Non unified memory architecture)
In many cases, GPU sits idle because either OS is scheduled poorly or CPU can’t feed the data fast enough to GPU. Some of the optimizations include setting CPU affinity to avoid cross numa node traffic. Example if the GPU running on node 1 requires data from CPU which runs on node 0 it needs transfer data across internode link which can contribute to latency.
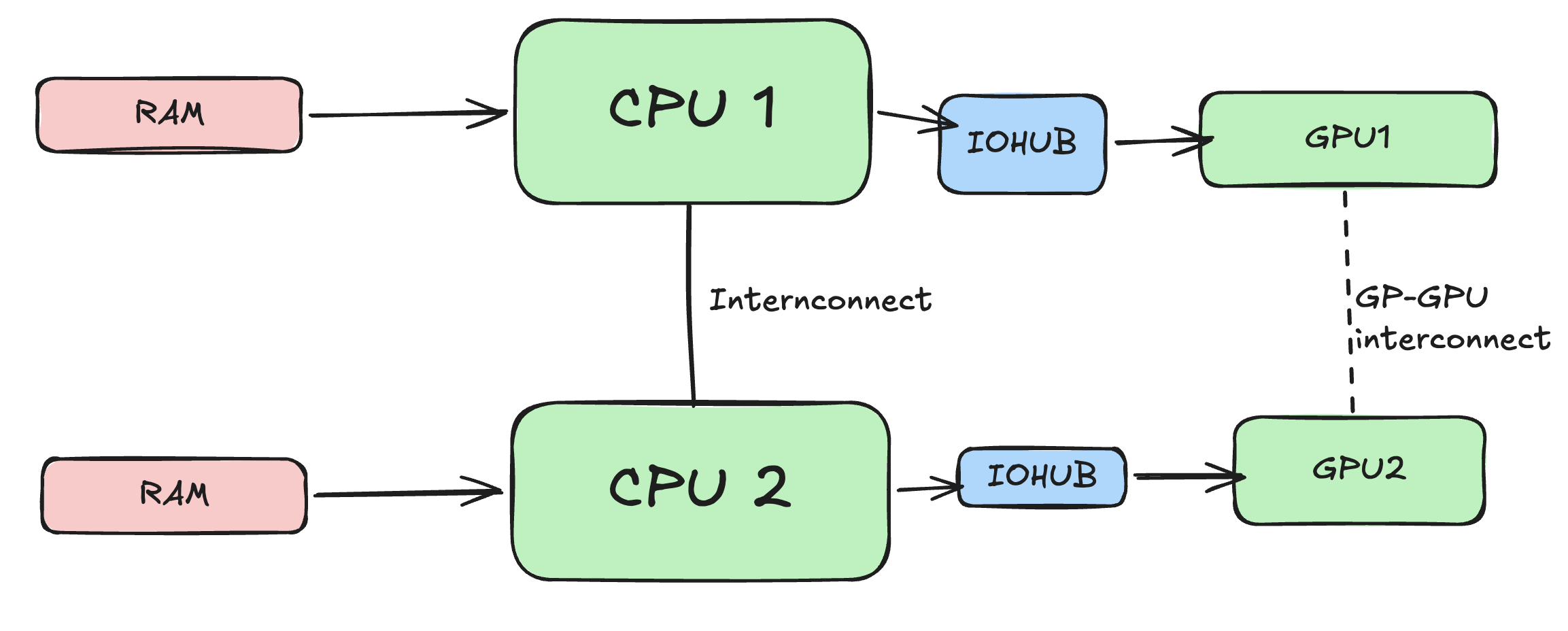
For running a training process on a CPU core, each CPU process should be Pinned based on its affinity to the GPU. numactl provides a way to bind processes based on its affinity.
numactl --cpunodebind=1 --membind=1 \
python train.py --gpu 4If numa affinity is not known, nvidia-smi topo can be used to both find affinity and bind cpu processes
#!/bin/bash
for GPU in 0 1 2 3; do
# Query NUMA node for this GPU
NODE=$(nvidia-smi topo -m -i $GPU \
| awk '/NUMA Affinity/ {print $NF}')
# Launch the training process pinned to that NUMA node
numactl --cpunodebind=$NODE --membind=$NODE \
bash -c "CUDA_VISIBLE_DEVICES=$GPU python train.py --gpu $GPU"
donepin_memory=True and use non_blocking=True to page-lock those buffers so that the host (CPU) cannot swap it to slower memory.
It’s important to note that the OS has a limit on how much memory a user can lock (pin). This is set with the ulimit -l
A DMA (Direct Memory Access) engine is dedicated hardware whose entire job is shoveling bytes between two addresses. The CPU just writes a small descriptor — source address, destination address, length — kicks the engine off, and goes back to other work. The engine streams the data across the bus on its own and raises an interrupt when it’s done. These engines live all over a system: in the PCIe root complex, inside NICs, inside NVMe controllers, and inside GPUs (NVIDIA calls the GPU’s versions copy engines). When you cudaMemcpy from pinned host memory to the GPU, it’s the GPU’s copy engine reading your RAM over PCIe by DMA. The catch : a DMA engine works with physical addresses and streams autonomously, so the source pages must stay put — they can’t be swapped out or relocated mid-transfer.
RDMA is that same idea stretched across a network. An RDMA-capable NIC on machine A can write straight into a specific memory region on machine B — without the remote CPU touching the data, and without either side going through the kernel’s TCP/IP stack. The app registers a memory region, posts a work request to the NIC’s queue, and the NIC’s DMA engine carries out the transfer end to end. Three properties make it fast: kernel bypass (the app talks to the NIC directly), zero-copy (no bouncing through OS buffers), and CPU offload (the remote CPU is never interrupted to handle the data). InfiniBand, RoCE, and iWARP are the common flavors. GPUDirect RDMA from your passage is exactly this, with the endpoint being GPU memory instead of host RAM: the NIC DMAs across the wire directly into another box’s GPU, skipping both hosts entirely.
1.2.1 HugePages and memory Allocator
THP -> Can help in reducing the memory overhead by making memory chunks bigger, TLB (Translation lookaside buffer) maps this virtual address to the pyhsical address in the memory. Larger hugepages means TLB has to spend less time finding the page. However for inference workloads where data can vary if memory becomes full or near full, compaction takes places which reshuffles memory blocks and can harm the performance. General consensus is to disable THP for inference or us madvise to only have THP for certain cases (KV cache or matrices)
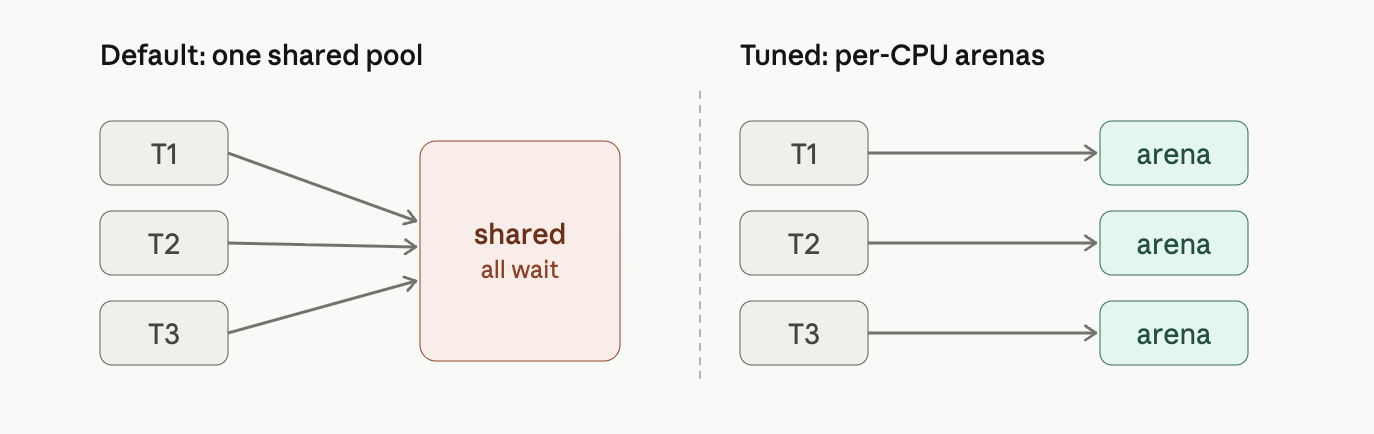 jemalloc and tcmalloc are smarter replacement allocators that attack exactly these. Every knob in your passage does one of two simple things: Give each thread/CPU its own private stash so nobody waits in line. In jemalloc, narenas:8 splits the one pool into eight separate ones (the right side of the picture above).
jemalloc and tcmalloc are smarter replacement allocators that attack exactly these. Every knob in your passage does one of two simple things: Give each thread/CPU its own private stash so nobody waits in line. In jemalloc, narenas:8 splits the one pool into eight separate ones (the right side of the picture above).
In tcmalloc, TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=512MB makes each thread’s personal cache bigger, so small allocations get served right out of that local cache without touching the shared lock or the OS at all. Hold onto freed memory and reuse it instead of bouncing it back to the OS. In jemalloc, the long dirty_decay_ms/muzzy_decay_ms (10000 ms = 10 seconds) tell it “don’t rush to return freed pages — keep them around to reuse,” which cuts those slow OS trips. tcmalloc’s TCMALLOC_RELEASE_RATE is the same dial: it sets how eagerly free memory goes back to the OS, so you tune it to return excess without churning. And jemalloc’s background_thread:true moves the cleanup work (returning/purging old pages) onto a side helper thread, so it happens off to the side instead of in the middle of your batch-prep, where it would cause a pause.
1.3 GPU Driver and runtime optimization
Some GPU driver settings to improve and boot performance
Keep GPU running as initializing a GPU can incur additional overhead. nvidia-persistenced keeps driver loaded and running even when no application is using the GPU (Higher power draw)
1.3.1 MPS (Multi Process Service)
When multiple processes share one GPU, the scheduler time-slices between them—running one process’s kernel, then another’s. With short kernels and idle gaps in between, the GPU wastes time on “ping-pong” context switches and underutilizes its resources. NVIDIA’s MPS lets multiple processes run on the GPU concurrently instead of strictly time-slicing. It merges their contexts into a single scheduler context, so the GPU can execute kernels from different processes simultaneously whenever resources (SMs, Tensor Cores, etc.) are free—avoiding the cost of switching and idling between processes.
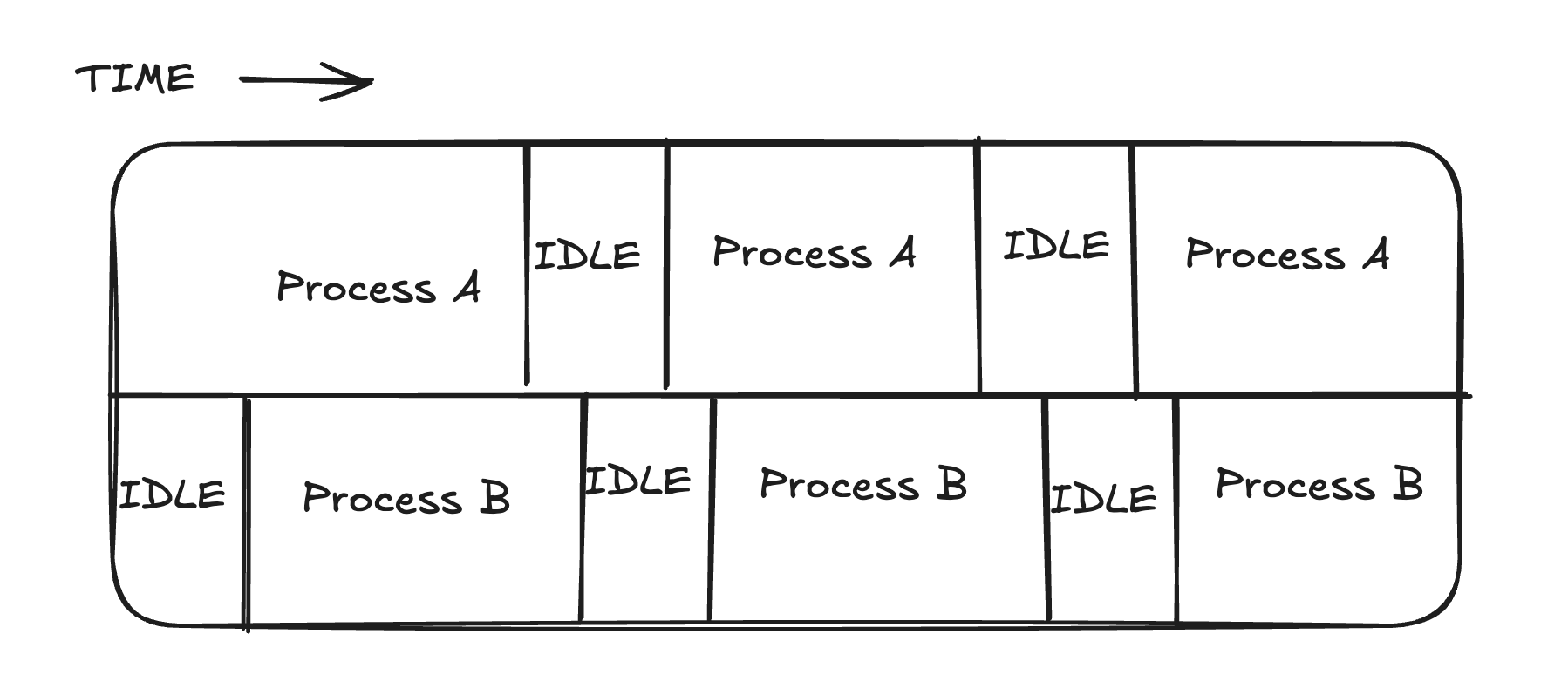
When is it useful? Not so much for training, where you typically run one process per GPU. But it’s a game changer for running many inference jobs on one large GPU. For example, four inference jobs on a 40 GB GPU, each using 5–10 GB and only ~30% of compute: by default each gets a time-slice, so only one runs at a time, leaving the GPU ~70% idle on average. MPS lets them run concurrently and reclaim that idle capacity.
Earlier we covered what MPS does at a high level: it lets multiple processes run kernels on the GPU concurrently instead of strictly time-slicing, so they can overlap and fill idle capacity. This phrase is about a specific control MPS gives you on top of that—a way to cap how much of the GPU each process is allowed to grab. The problem it solves: plain MPS lets processes run concurrently, but it doesn’t stop one greedy process from hogging the compute. If one process launches enough kernels to saturate all the SMs, the others get starved—they’re sharing, but not fairly. Concurrency alone doesn’t guarantee anyone a slice. The active thread percentage is the knob that fixes this. The GPU’s compute capacity lives in its streaming multiprocessors (SMs), and “active thread percentage” sets the maximum fraction of those SMs a given process is allowed to use at once. You set it per client (per process) via an environment variable, CUDA_MPS_ACTIVE_THREAD_PERCENTAGE. So if you have four inference jobs sharing one GPU and you want them to share evenly, you give each one 25%. Now no single job can occupy more than a quarter of the SMs, and the four coexist without trampling each other.
1.3.2 MIG (Multi instance GPU)
Its nvidia’s way of physically partitioning a single GPU into smaller fully isolated GPU instances each with its own hardware, caches and copy engines. MIG carves out each GPU such that one instance cannot accidently touch other instances resources, which gives predictable performance and noisy neighbor solution A profile like MIG 3g.90gb means 3 compute slices (“3g”) and 90 GB of memory. Under the hood, NVIDIA splits a GPU into 7 compute slices and 8 memory slices—that asymmetry is why you see fractions over 7 and over 8 in the table. Here’s what each column means:
- Profile name — the partition recipe: {N}g is how many of the 7 compute slices it gets, and .{X}gb is the memory it gets. The B200 has 180 GB total, so the fractions map directly: 1/8 of 180 ≈ 23 GB, 2/8 = 45 GB, 4/8 = 90 GB, full = 180 GB.
- Fraction of memory — share of the GPU’s memory (HBM), divided into 8 units. So 1/8, 2/8, 4/8, up to full.
- Fraction of SMs — share of the streaming multiprocessors (the actual compute cores), divided into 7. So 1/7, 2/7, 3/7, 4/7, up to full. L2 cache size — share of the on-chip L2 cache, which tracks the memory fraction (the cache is tied to the memory partition). Copy engines — dedicated DMA engines for moving data in and out of the instance; bigger instances get more (2 → 16).
1.3.3 OOM (Out of Memory Subscription) GPU
GPU does not have something like memory swap like Operating system. If more memory is required, OOM error will occur and the process will crash. Tensorflow by default allocates the entire available memory by default, whereas pytorch only allocates what the application need. The GPU-to-CPU memory offloading can be slow, however CPU memory I/O is slower than GPU high-bandwidth memory (HBM) I/O.
Normally with CUDA, the CPU and the GPU have separate memory, and you have to manage both yourself: allocate space in CPU RAM, allocate space in GPU memory, and explicitly copy data back and forth (cudaMemcpy) before and after the GPU does its work. It’s fast but tedious and easy to get wrong. Unified Memory hides that split. You allocate one pointer that “just works” on both the CPU and the GPU, and the CUDA runtime figures out where the data actually needs to be at any moment and moves it for you. You write simpler code; the system handles the shuttling. The catch is how it moves the data. Memory is organized into chunks called pages. With on-demand paging, the GPU doesn’t copy everything up front—it waits until a kernel actually touches a page that isn’t currently in GPU memory. At that moment the GPU hits a page fault (essentially “I need this data and don’t have it”), and the Page Migration Engine fetches that page from CPU RAM across the bus (PCIe or NVLink) into GPU memory. The PME is the dedicated hardware that does this migration automatically, and on Hopper/Blackwell it also handles the reverse: when GPU memory fills up, it can evict pages back to CPU RAM. That last part is what lets you “oversubscribe”—work with a dataset bigger than the GPU’s physical memory.
1.4 Kubernetes and topology manager
Nvidia Kubernetes GPU operator manages all the installation and lifecycle process for the nvidia software. Kubernetes is however not topology aware and may try to allocate nodes which do have the same NUMA affinity.
1.4.1 Topology manager
Topology manager is a component of kubelet that manages how resources should be allocated for a particular pod, so that they all come from the same place in the machine. This helps in running workloads by optimizing and exploiting their numa affinity (The same can be done manually by labelling nodes with same GPU so only pods with those same labels get assigned to the labelled nodes). There are different policies using which topology manager assigns resources
- none — the default; no coordination (the old scattered behavior).
- best-effort — try to align everything on one NUMA node, but if it can’t, schedule the pod anyway.
- restricted — try to align; if it can’t satisfy the preferred alignment, refuse to admit the pod (it fails rather than running badly).
- single-numa-node — the strictest; require everything on a single NUMA node or reject the pod.
1.5 Key Takeaways
- Data locality is critical -> Use high speed NVMe SSD
- Implement NUMA aware affinity -> Use NUMA affinity and pin processes according to their affinity
- GPU driver and runtime efficieny -> MIG, MPS, Hugepages optimized to avoid OS swapping
- Tune networking stack: Use RDMA and RoCE for gradient and computation
- Orchestration and docker for consistency and best practices -> Use topology manager and mount filesystems